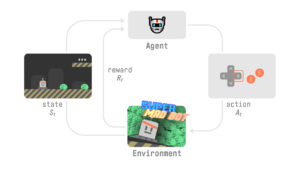
深層Qラーニング
ここは、深層学習を活用してQラーニングの最新技術のいくつかを紹介します。題材は、カートポール(倒立振子)です。DSS RLのプラグインを使用して、Deep Q-Learning(DQL)エージェントをトレーニングします。

目的
ここでは、次のことを説明します。
- ディープQラーニング(DQL)の基礎
- DSSのRLプラグインを使用してDQLを実装する方法
Qラーニングに深層学習を追加する
Q-Learningチュートリアルでは、エージェントがQ-Tableを使用して、ゲームの各ステップで実行する最適なアクションを選択する方法を学びました。このQテーブルは、現在の状態を前提として、アクションの予想される最大の将来の報酬を見つけるのに役立つ「チートシート」と考えることができます。
Qテーブルを使用することは良い戦略です。ただし、この戦略は常にスケーラブルであるとは限りません。
3D FPS(一人称シューティングゲーム)のようなゲームを想像してみてください。これは、巨大な状態空間(数百万の異なる状態)を持つ大規模な環境です。または、何百万もの情報(天気、日付、空席数、競争など)に基づいて航空券の価格を定義する必要があるエージェントについて考えてみてください。したがって、状態の規模は大きくなります。このような環境用のQテーブルの作成と更新は、数百万の可能な状態があるため、非常に非効率的です。
別の戦略は、ニューラルネットワークを使用することです。特定の状態について、このニューラルネットワークはその状態で可能なアクションごとに異なるQ値を概算できます。ニューラルネットワークはQ値を近似するため、未踏の状態に一般化することもできます。このタイプのニューラルネットワークは、Deep Q Network(DQN)と呼ばれます。
その結果、ニューラルネットワークは、状態で可能な各アクションのQ値を返すための入力として「状態」のみを必要とします。この単一の入力はQテーブルとは対照的です—Q値を返すために状態とアクションの両方を提供する必要があります。

例として、ビデオを考えてみましょう。この場合、DQNへの入力はフレーム(またはフレームのスタック)であり、ネットワークの予測出力は可能なアクションのQ値です。
DSSを使用したディープQネットワーク
Deep Q-Learningについて理解したので、DSSのRLプラグインを使用して、Cartpoleをプレイするエージェントをトレーニングしましょう。
Cartpoleは、OpenAI gym環境です。これは、小規模でシンプルな環境を使用して、エージェントが学習しているかどうかを確認できるライブラリです。
カートポールでは、カートを(左または右に押すことによって)制御します。目標は、ポールを平衡状態に保つことです。どのような状況でも、エージェントは何をすべきかを知ることができなければなりません。エージェントは、カートポールが平衡状態にあるすべてのタイムステップで勝ち(+1)、それ以外の場合は負け(-100)します。
プロジェクトを作成し、フォルダを準備します
新しいプロジェクトを作成し、次のような名前を付けます。
Deep Q-Learning with DSS
フローに2つのフォルダーを作成します。+Dataset のドロップダウンから、Folderを選択し、フォルダに名前を付けます。
- Saved Model に、トレーニング情報を含むJSONを含む保存されたモデルを含めます。
- Reply elements に、テスト情報を含むJSONを含めます。
これで、RLプラグインを使用する準備が整いました。
エージェントを訓練する
From the + Recipe dropdown, select Reinforcement Learning > Train.
レシピダイアログから Saved Model を選択し、Create Recipe をクリックします。

トレーニングダイアログでは、多くのハイパーパラメータにアクセスできます。 ハイパーパラメータは、学習アルゴリズムを適用する前に設定する必要のある変数です。
まず、environmnet で、環境を選択します。
- “Environment library”には、 OpenAI gym を選択します。
- “Environment” には、Cartpole v1 を選択します。

次に、使うエージェントを選択します。(この場合は、Deep Q-Learning Agent)
- “Agent” Deep Q-Learning を選択します。
次に、 policy を選択します。
- “Policy” MLP Policy を選択します。

探索パラメータとして、以下を設定します。
- “Exploration Fraction” 探査減衰率を、0.1 に設定します。
- “Exploration Min” 0.02 に設定します。
経験再生(Experience Replay)パラメータを以下のように設定します。
- “Buffer Size” 50000
- “Prioritized Replay” のチェックボックスをはずします。この概念については、ディープQ学習の改善に関する章で説明して使用します。
For the Deep Q improvements parameters:
- Check the “Double DQN” checkbox
- Set “Target Net update freq” to 500
トレーニングパラメータとして、以下を設定します。
- “Discount factor” 0.99. このハイパーパラメータにより、エージェントは、長期的な報酬に集中します。 この値が1に近いほど、エージェントは長期的な報酬に重点を置きます。
- “Learning Rate” 0.0005
- “Total training timesteps” 100000
- “Batch Size” 64
- “Train Frequency” 1.
Run をクリックして、エージェントを訓練します。
エージェントをテストする
訓練ができたので、性能をテストしましょう。 +Recipe ドロップダウン メニューから、Reinforcement Learning > Test を選択します。
レシピダイアログで、Saved Models を、 “Saved Models” フォルダに設定し、Saved Replays を、“Saved Replays” フォルダに設定します。 そして、Create をクリックします。

テストウィンドーで、以下の値を設定します。
- “Environment library” OpenAI Gym
- “Environment” Cartpole v1
- “Agent” Deep Q-learning (DQN)
Run をクリックします。

テスト結果を表示します。
これで、強化学習ウェブアプリをとつかってテスト結果を表示できるようになりました。
Code menu > Webapps に行き、+New Webapp > Visual Webapp > RL Agent Testing Results を選択します。
ウェブアプリに名前をつけて、Create をクリックします。

次に、テスト結果のJSONファイルが保存されている Replay Folder を選択します。

Save and view webapp をクリックします。
これで、平均テストスコアとトレーニングハイパーパラメータを確認できます。

結論
DeepQ-Learningを使用してカートポールのプレイを学習するエージェントをトレーニングしました。 次に、ハイパーパラメータを変更して、より良い結果が得られるかどうかを確認します。 他の環境で試してみてください(たとえば、車が山に登る必要がある環境であるMountainCar v0を使用します)。 ハイパーパラメータを変更してみてください。